The first synthesized structured & unstructured data platform
VAST DataBase
The VAST DataBase redefines traditional database tradeoffs by delivering the transactional performance of a database with the query efficiency of an exabyte-scalable data warehouse, all at the cost of a data lake. Like modern AI applications, the VAST Data Platform supports both unstructured and structured data applications.
Introduced in 2019, VAST’s Multi-Protocol DataStore is the world’s first file and object storage system, blending the performance of all-flash with the economics of an archive. This multi-protocol data management system, supporting NFS, SMB, and S3, is designed to serve diverse data needs. With the VAST DataBase, unstructured data gets more than a data catalog – the DataBase’s transactional and analytical capabilities lay the foundation for the semantic layer of AI training and inference systems.
Content Recommendation
By enabling real-time queries all the way down to the archive, the VAST Database enables content producers, e-commerce sites and social networks to query user interest profiles and to real-time and train new ML models.
Payment Fraud Analytics
The VAST DataBase transforms fraud analytics by combining the transactional performance of a database with the scalable query performance of a data lake. By breaking the tradeoffs between a database and a data warehouse, the VAST DataBase enables payments providers to analyze and detect fraud in real time.
Targeted Advertising
The VAST DataBase is used by leading advertisers and advertising networks to develop more targeted advertising techniques by mapping and correlating user behavior. VAST’s efficiency algorithms create all-flash data lakes with archive economics, ideal for optimizing ad network P&L.
Homeland Security
The VAST DataBase brings the ability to perform fine-grained queries all the way down to the archive. The platform is ideal for government agencies who struggle to find needles in haystacks… now, these needles can be found in real-time at exabyte-scale.
Breaking the Tradeoffs Between Transactions and Queries
VAST systems leverage deep write buffers built from low-cost persistent memory, this allows for every ACID transaction to be stored instantaneously.
As tables fill, they are then migrated down to low-cost hyperscale flash and stored in a columnar format, so that queries also run instantaneously.
Queries cut across both the long-term datastore and the write buffer, and even though data accessed in the buffer is row-based, the underlying persistent memory structures make any row reads lightning fast.
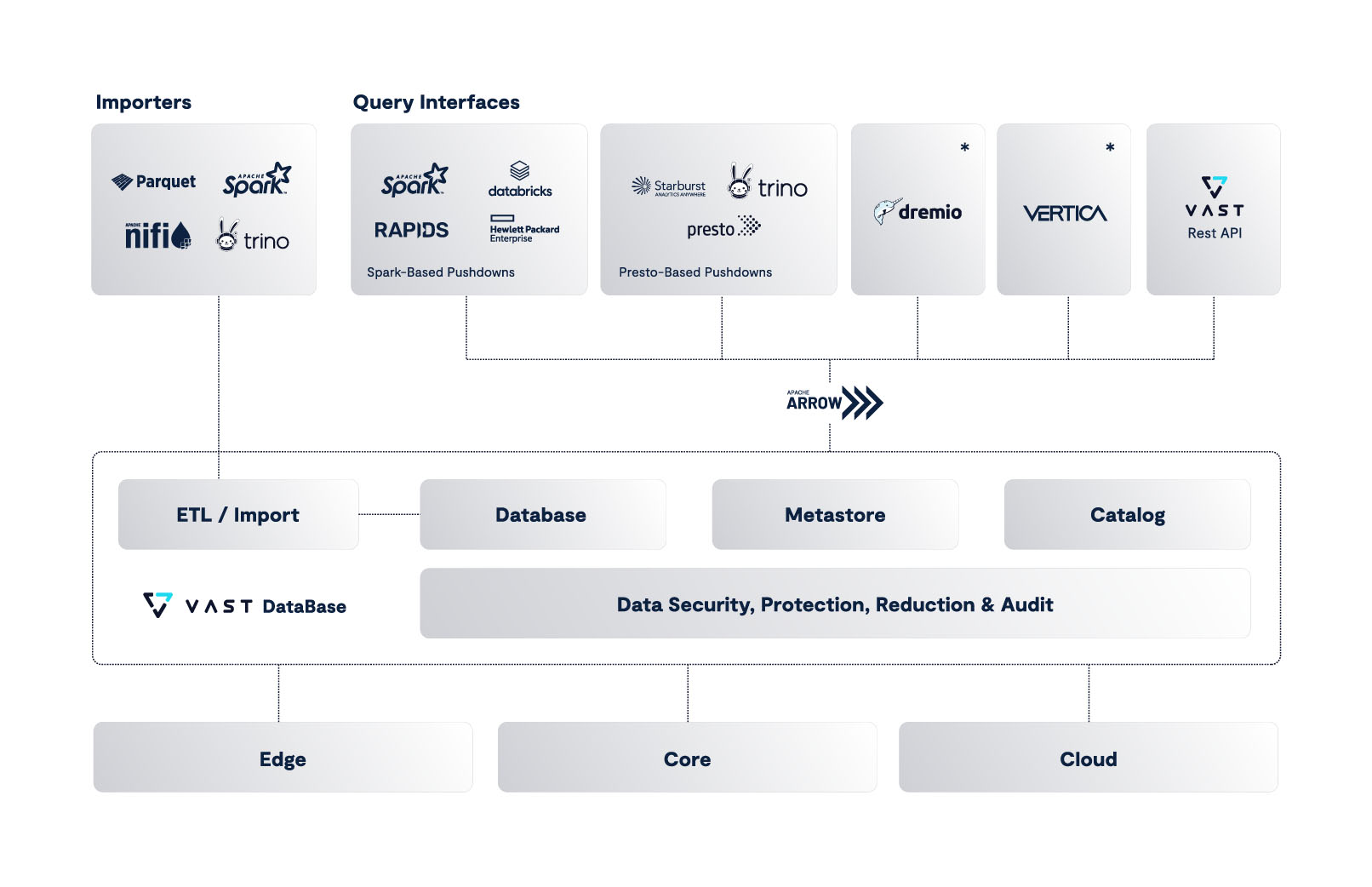
The VAST DataBase Embraces Open Data Science Standards
The VAST DataBase uniquely combines an exabyte scale namespace for natural data types like images, video, LIDAR, genomes, and other rich, real-world data sources, along with a tabular database to hold the catalog of expanding metadata about the objects generated as data works its way through the deep learning pipeline.